Weekly Evidence Roundup · April 27, 2026
Cardiology AI is bifurcated by task. The fine print on both sides changes the read.
What They Found A new systematic review in JMIR Cardio pooled 33 studies that put large language models to work across the full spread of cardiology tasks: chronic conditions, acute events, physician education, patient education, and diagnostic interpretation. The risk-of-bias assessment used an
What They Found
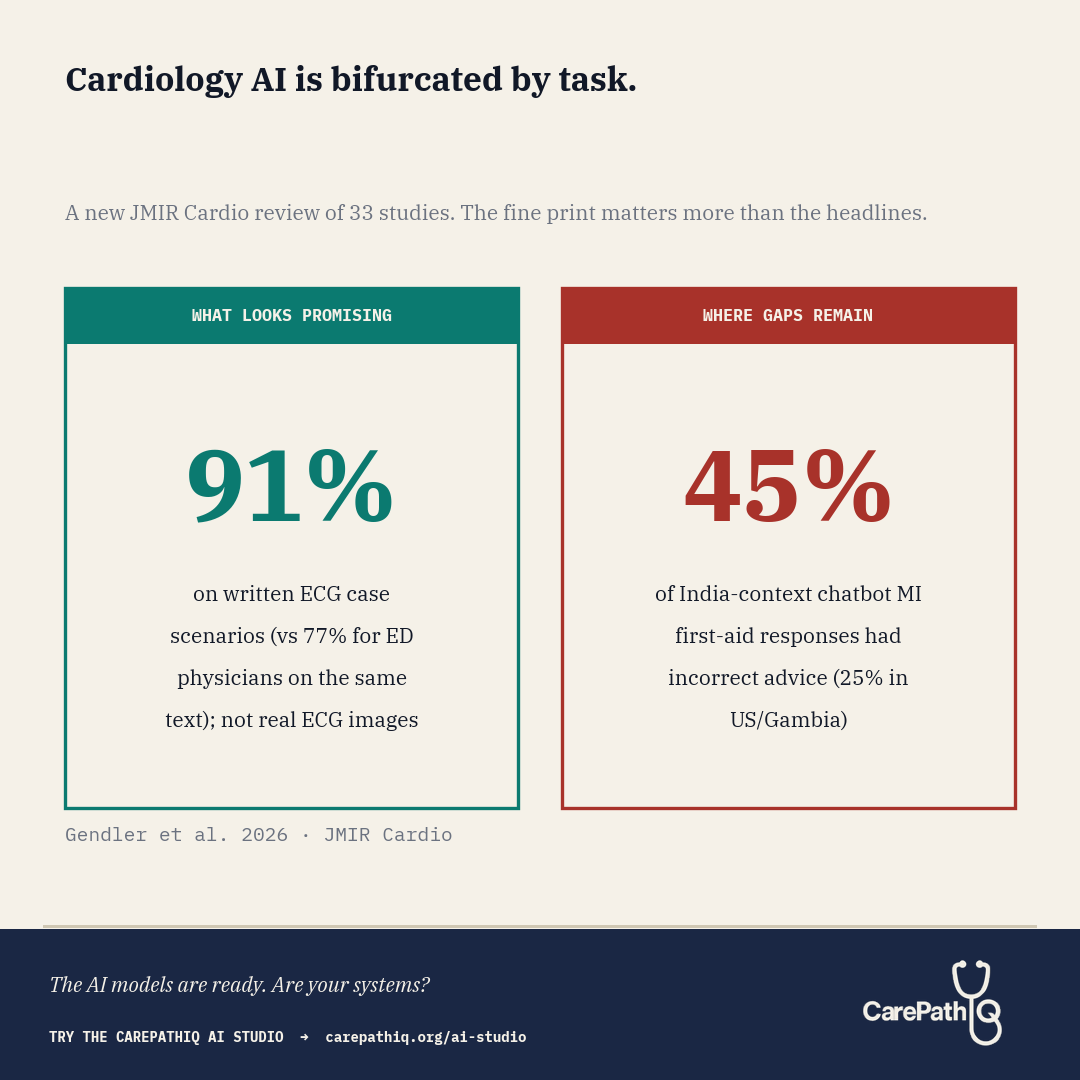
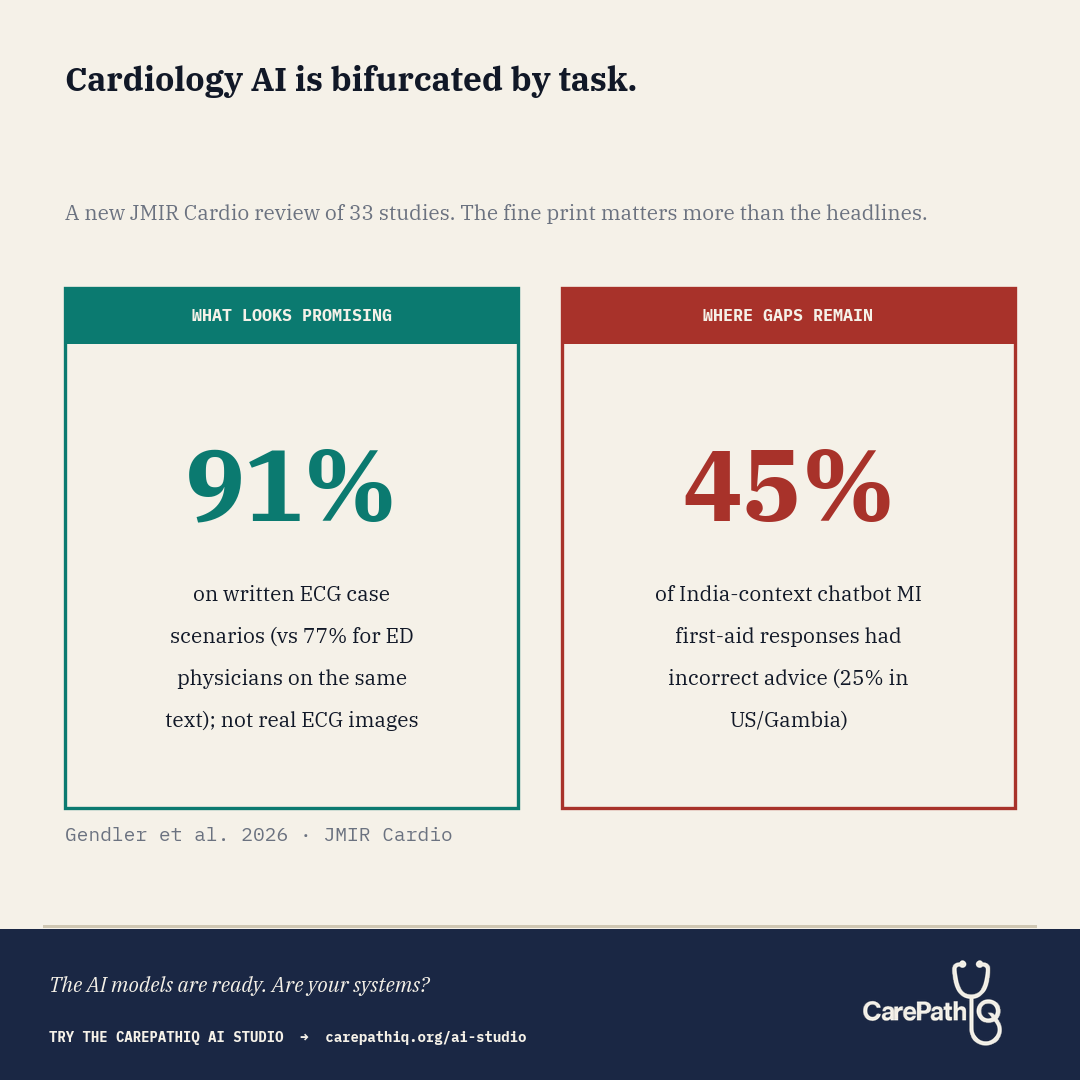
A new systematic review in JMIR Cardio pooled 33 studies that put large language models to work across the full spread of cardiology tasks: chronic conditions, acute events, physician education, patient education, and diagnostic interpretation. The risk-of-bias assessment used an adapted QUADAS-2 tool, and the protocol was registered with PROSPERO. The picture that emerges suggests something more useful than a single overall accuracy number: cardiology-AI performance appears to vary more by task type than by vendor.
Gendler et al. report that ChatGPT-4 answered ECG case scenarios correctly in 91% of cases (36 of 40), compared with 77% (31 of 40) for emergency physicians answering the same scenarios (P below .001). The source study is Günay et al. 2024 in Am J Emerg Med, and a critical detail surfaces in the full text: those 40 “vignettes” were written textual descriptions of ECG findings, not actual ECG images. The systematic review’s own assessment of that study notes “used text, not real ECG images; possible training exposure.” So the comparison was between a model answering text-based ECG questions and physicians answering the same text, not between a model reading an ECG and a physician reading one at the bedside. ChatGPT-3.5 answered 91% of heart failure questions accurately (43 of 47), though responses required college-level reading comprehension. On the acute side, Birkun and Gautam (Curr Probl Cardiol, 2024) tested Bing Chat on patient-facing first-aid advice for suspected myocardial infarction across three country contexts. Incorrect advice appeared in 25% (5/20) of responses for Gambia and the United States and 45% (9/20) for India. The systematic review notes that omissions of guideline-concordant steps were also frequent, though without a single pooled percentage. The geographic gap is itself a finding: chatbot performance on time-critical patient guidance varied by country, plausibly tracking Western-skewed training data. On board-style physician questions, ChatGPT-4 outperformed ChatGPT-3.5 (66% vs 38%). On patient education, the readability gap returned: scientifically adequate explanations were written at an 11th-grade level when hospital materials target 7th grade.
A reasonable read of a 33-study sample is not that LLMs work or do not work in cardiology. It is that they appear to work for some tasks and to struggle in specific, repeatable ways on others.
What the Numbers Don’t Capture
The ECG comparison deserves a pause before it gets quoted in a procurement deck. The Günay et al. study used textual case scenarios, not ECG images — meaning the task being scored was reading-comprehension on ECG descriptions, not pattern recognition on actual tracings. That is a fundamentally different task from what an ED physician does at the bedside, where ECG reading is a 30-to-90-second triage decision under workflow pressure: rule out STEMI, rule out an unstable rhythm, rule out ischemia, move on. A model with unlimited time, isolated focus, and a clean text prompt is not a fair comparator for a clinician reading an actual 12-lead under triage load.
A few other limitations worth flagging. The N (40 scenarios) is thin: 36 of 40 versus 31 of 40 is a five-scenario gap. Inter-rater reliability on ECG interpretation is not strong even among cardiologists, so a couple of disagreements about ground truth could move the headline. The systematic review explicitly flags “possible training exposure” as a concern for the Günay study: if any of the textual ECG cases were in ChatGPT-4’s training data, the model is recalling rather than reasoning. The review describes most primary studies as small in silico designs with high or moderate risk of bias. Aggregate accuracy also obscures clinical severity: a 91% that performs well on textbook STEMI descriptions but underrepresents Wellens, posterior MI, hyperacute T-waves, or de-Winter patterns is not the same 91% in a department where those are the diagnoses you cannot afford to miss.
And calibration is unmeasured. When a physician is uncertain about an ECG, we ask for another read or call cardiology. When the model is wrong, does it know? Until that question is answered prospectively, 91% on text vignettes is a benchmark, not a deployment-readiness signal.
Why It Matters Now
For those of us in the ED, this bifurcation lands on both ends of a shift. The text-based ECG signal is suggestive but does not yet translate into “the model can read a real ECG faster than I can.” The acute-guidance gap may already be reaching us in the form of patients who consulted a chatbot before deciding whether to come in, and the geographic disparity in Birkun and Gautam’s data is its own warning: the patients most likely to receive incomplete chatbot first-aid advice may also be those least connected to a familiar care setting on arrival. A review like this one may help health systems sort cardiology-AI use cases into supervised pilots, scaffolded workflows, and use cases not yet ready for patient-facing deployment.
A more useful framing for cardiology AI may be less “does it work?” and more “for which task, with which scaffolding, and with what reading-level safeguards before our patients see it?”
What CarePathIQ Is Building in Response
CarePathIQ’s pathway architecture, built by an emergency physician with board certification in clinical informatics for the whole multidisciplinary care team, is being designed for exactly this kind of triage. The AI Studio is meant to scaffold AI into specific decision nodes: structured where models look strong, with explicit handoffs and reading-level checks where they look weak. Free and open access, for clinicians, pharmacists, nurses, and informaticists building cardiology pathways their patients can actually read before reaching the department.
Try the CarePathIQ AI Studio → carepathiq.org/ai-studio